
近日伯克利 RISE Lab 开源了一个多数据流实时分布式分析系统 Confluo,它即是一个网络监控和诊断框架,也可以作为时序数据库和发布订阅消息系统。
当下,类似基于终端主机的网络监控系统、IoT 设备传感器程序等应用,其后端的服务器每秒都可以捕获数千万个数据点。这些数据被用于在线查询,实现可视化与监控,或者用于离线查询,进行故障分析和系统优化。
这样的使用场景下,就需要实时监控和分析工具支持,这些工具通常支持高吞吐量数据提取、低延迟在线查询和低开销的离线查询。
虽然目前已经存在一些用于高吞吐量数据提取的数据结构,它们可以支持丰富的在线和离线查询,但是高吞吐量与查询能力目前来看还是互斥的。在从多个数据流提取数据时,查询需要更新多个数据结构,包括原始数据、聚合统计信息和物化视图。
但是用于支持这些查询的数据结构往往具有较高的更新开销,而且无法维持大多数应用程序所需的数据提取速率。而另一方面,可以维持高数据提取速率的数据结构往往只支持非常简单的查询。
Confluo 正是为了应对这种情况而产生的,它是一个致力于同时实现高吞吐量数据提取和富有表现力的离线/在线查询的系统。
-
来自多个数据流的数百万个数据点的高吞吐量并发写入
-
毫秒级的在线查询
-
使用最少 CPU 资源的 ad-hoc 查询
-
作为一个网络监控和诊断框架,Confluo 能够在单核上以线路速率(10Gbps 链路)执行数千个触发器和数十个过滤器。
-
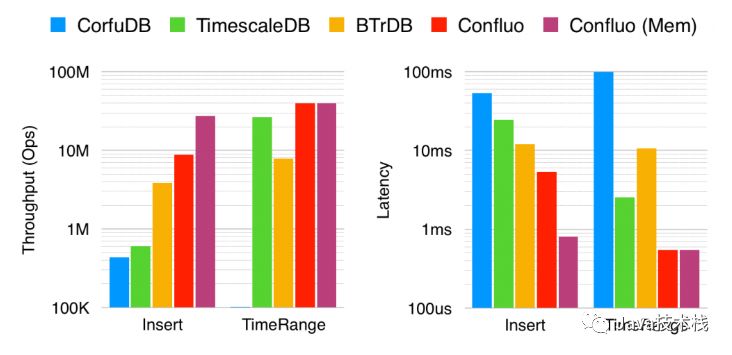
作为一个时序数据库,与其它诸如 CorfuDB、TimescaleDB 和 BTrDB 等先进的时序数据库相比,Confluo 的吞吐量提高了 2 到 20 倍,写入延迟降低了 2 至 10 倍,时间区间查询延迟降低了 5 至 20 倍。
-
作为一个发布订阅消息系统,Confluo 的吐量是 Kafka 的 4 到 10 倍。
更详细的分析:
https://rise.cs.berkeley.edu/blog/confluo-millisecond-level-queries-on-large-scale-streaming-data
相关链接
-
来源:oschina.net/news/102795/ucberkeley-riselab-opensource-confluo
-
下载:github.com/ucbrise/confluo
对此,你怎么看?
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



