大家好,我是R哥。
你是不是被 DeepSeek-R1 1.5b、7b、8b、14b、32b、70b、671b 这些概念绕晕了?
如图所示:
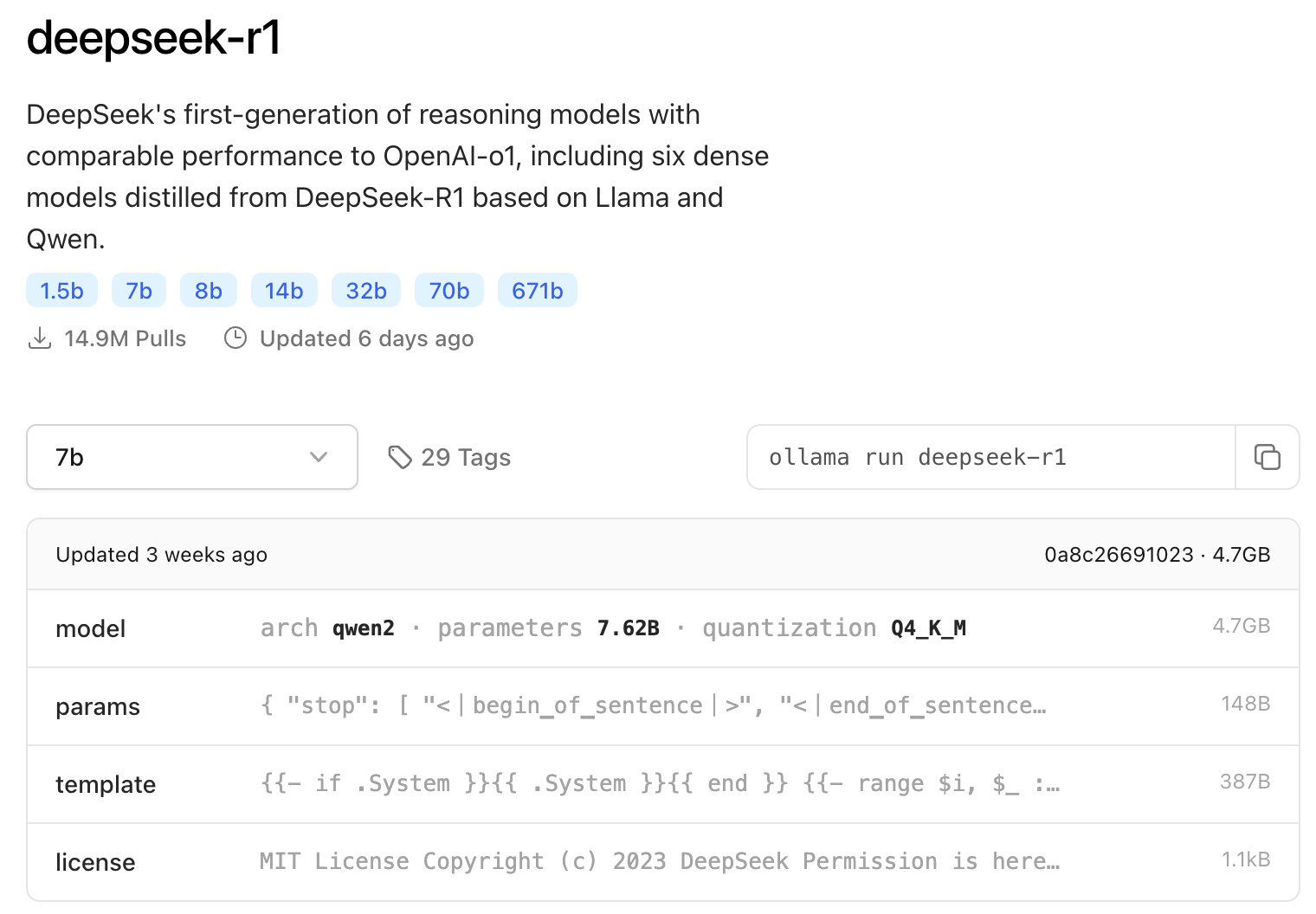
DeepSeek-R1 模型有好几种规格,比如 1.5b、7b、8b、14b、32b、70b、671b,后面的数字代表模型的参数量,而 b 则是指 “billion” 的意思,也就是十亿,表示这个模型有多少亿个参数:
- 1.5b 有 15 亿个参数;
- 7b 是 70 亿个参数;
- 8b 是 80 亿个参数;
- 14b 是 140 亿个参数;
- 32b 是 320 亿个参数;
- 70b 是 700 亿个参数;
- 671b 是 6710 亿个参数。
其中,671b 就是指传说中的 “满血版”,性能最强,也就是官网部署的版本。
这样命名并不是 DeepSeek 的独特之处,其他大模型也都是这样命名的,比如说 llama:
参数量直接决定了一个模型的计算能力和硬件需求,一般来说:
- 参数越大: 代表模型越聪明,对复杂问题的处理能力越强,但对算力和硬件的要求也越高。
- 参数越小: 代表模型越轻量化,对算力和硬件的要求越低,适合资源受限的设备。
所以,一个模型的参数量越大,它能处理和生成的内容质量越复杂、越高,也更能满足我们的要求,不过也需要更多的硬件资源来支撑。
问题来了:参数量越大越好吗?
大家可能会觉得,既然参数量越大模型越聪明,那是不是直接用最大的参数量就完事了?
其实,这并不一定,现实中,参数量大 ≠ 适合所有场景,得具体问题具体分析。
比如以下几个场景:
1、轻量化设备上的推理需求
如果你想在手机、嵌入式设备或者单片机上部署一个模型,那么像 671b 这种 “猛兽” 显然是不现实的。
这时候更小的参数量(比如 1.5b 或 7b)就显得非常有优势,它们对算力要求低,响应速度快,适合低功耗设备运行。
举个例子:我们手机里的语音助手,比如 Siri、Google Assistant、小爱同学等语音助手,就需要采用这种轻量化模型。
2、超大规模的推理和复杂应用
而对于一些高精尖的应用场景,比如大型内容生成、医学影像诊断或者金融预测等,这些任务需要处理复杂数据并生成高质量结果,那就需要依赖大模型了。
像 70b 或 671b 这样的超大模型就很适合这些高算力场景,尤其是在数据中心或云端运行时,这些参数多的大模型可以提供更准确的结果。
DeepSeek-R1 系列模型的规格划分主要是为了适应不同场景的需求,从小到大覆盖了轻量化应用到高算力推理的各种场景。
在实际应用中,我们需要根据算力、成本、业务需求等综合因素来选择合适的模型。
所以大家不用被参数量这些数字吓到,记住一点:适合自己的,才是最好的!
最后,如果你还没用过 DeepSeek,清华大学出的《DeepSeek 从入门到精通》推荐你好好看看吧,质量非常高,从原理到应用实践,写得非常好。
未完待续,公众号持续分享「DeepSeek」及 AI 实战干货,关注「AI技术宅」公众号和我一起学 AI。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



