大家好,我是 R 哥。
最近,AI 界又掀起了一股新的浪潮,尤其是在国内市场,春节期间甚至被 DeepSeek 刷屏了,大家都在讨论 DeepSeek,好不热闹。
那么,DeepSeek 究竟是什么?它有什么厉害的地方?
啥?你还不知道使用 DeepSeek?清华大学出的《DeepSeek 从入门到精通》使用手册,好好看看。
今天,R 哥就带大家来一探究竟。
DeepSeek 是国内一款开源的大模型,主打通用 AI 能力,类似于 OpenAI 的 GPT 系列,目标是打造国产的、强大的、开放的大语言模型。
DeepSeek 在今年春节期间迅速爆红,并凭借强劲的性能,获得了大量开发者的关注,它最大的特点是开源、使用成本低,并且性能不输 ChatGPT。
ai.com 这个域名之前跳转的是 ChatGPT,现在跳到 DeepSeek,可知 DeepSeek 的火爆程度。
DeepSeek 主要有以下几个大模型:
- DeepSeek R1(最新最强大)
- DeepSeek V3
- DeepSeek Coder V2
- DeepSeek VL
- DeepSeek V2
- DeepSeek Coder
- DeepSeek Math
- DeepSeek LLM
以 DeepSeek-R1 为例,满血版本为:671B,还有几个蒸馏版本:
| Model | Base Model |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct |
模型下载:
DeepSeek 之所以能迅速崛起,主要是因为它在技术上有一些独特的优势。
DeepSeek 采用了 Mixture of Experts(MoE,混合专家模型),这一架构让它可以在计算资源相对有限的情况下,仍然保持高性能,实现了它对 OpenAI 的弯道超车。
MoE 的核心思想是:
不是所有参数都在每次推理时被激活,而是只有一部分专家(Experts)在工作,这样可以减少计算成本,同时 提高模型的推理效率。
相比于 OpenAI 的 GPT-4,DeepSeek 的 MoE 版本可以用更少的计算量,获得接近 GPT-4 级别的性能。
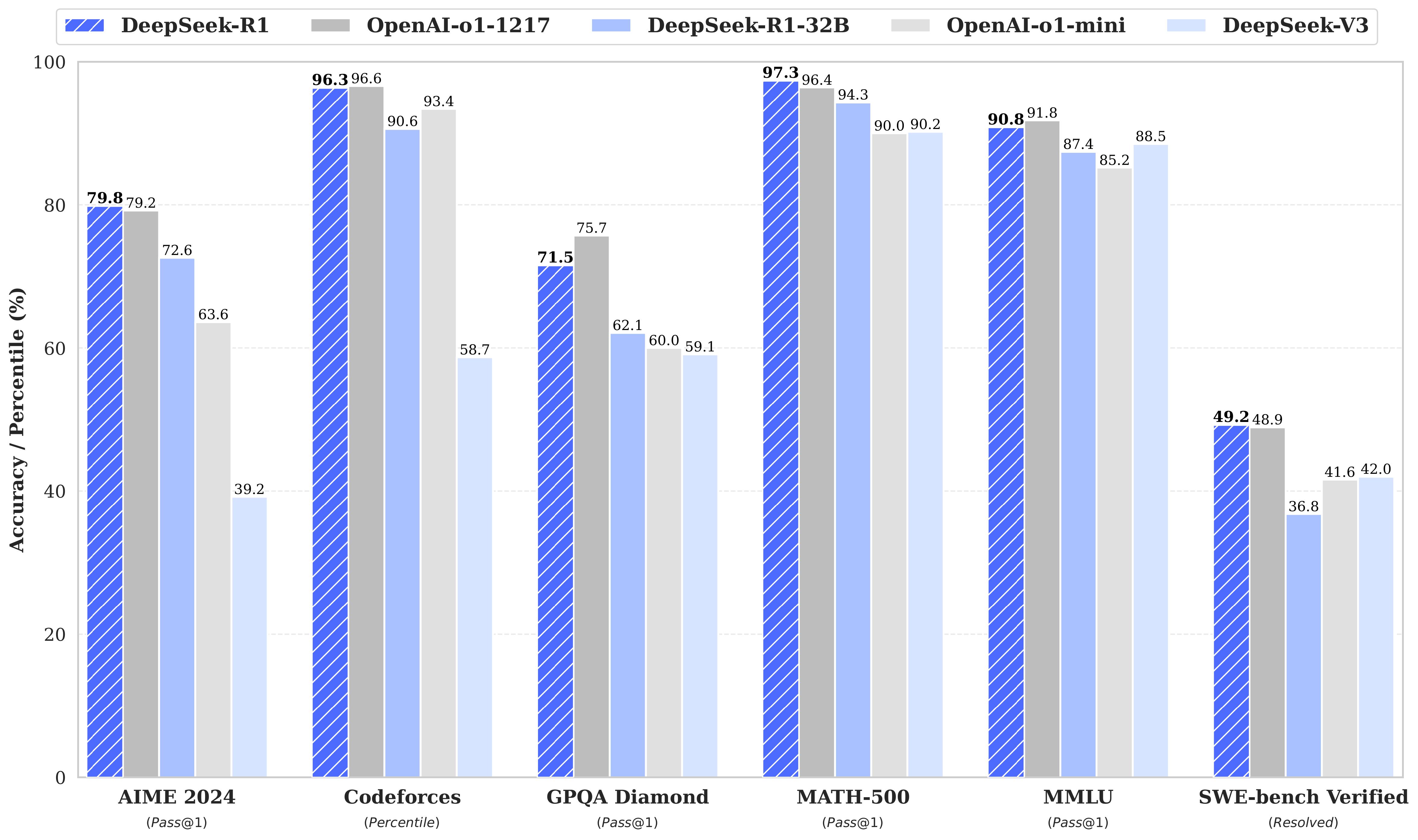
既然 DeepSeek 是国产大模型,那么,它和 GPT-4 的差距在哪里?
| 对比项 | DeepSeek | GPT-4 |
|---|---|---|
| 是否开源 | ✅ 开源 | ❌ 闭源 |
| 中文优化 | ✅ 很强 | ✅ 强 |
| 代码能力 | ✅ 强 | ✅ 更强 |
| 推理速度 | ✅ 轻量级 MoE 优势 | ❌ 需要更大计算资源 |
| 本地部署 | ✅ 可以 | ❌ 不能 |
| 使用限制 | ✅ 自由可商用 | ❌ 需要 API 访问 |
DeepSeek 的最大优势是 开源 和 中文优化好,比 GPT-4 更适合 本地部署 和 企业使用,所以它特别适合 中文 AI 应用、代码辅助开发 等场景。
如果你对 AI 感兴趣,或者想尝试本地部署一个强大的大语言模型,DeepSeek 绝对值得一试!
DeepSeek 官网:
DeepSeek 可视化聊天:
DeepSeek 开放平台:
DeepSeek 接口文档:
DeepSeek 可视化聊天是免费的,接入 API 是付费的,不过相比 OpenAI 要便宜太多了,这也是它的优势。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



